 画像ソース: Unbounded AI によって生成8 月 16 日、OpenAI チームは AI の新たな利用法、つまりコンテンツ ポリシーの開発とコンテンツ モデレーションの決定に GPT-4 を使用することを発表しました。これにより、より一貫性のあるラベル付け、ポリシー改良のためのより迅速なフィードバック ループが可能になり、手動レビュー参加者の参加が減少します。コンテンツのモデレーションは、デジタル プラットフォームの健全性を維持する上で重要な役割を果たします。 OpenAI の研究者は、GPT-4 を使用したコンテンツ モデレーション システムにより、ポリシーの変更をはるかに高速に繰り返すことができ、サイクル タイムが数か月から数時間に短縮されることを発見しました。同時に、GPT-4 は、長いコンテンツ ポリシー文書のルールとニュアンスを解釈し、ポリシーの更新に即座に適応することもできるため、より一貫性のあるラベルが得られます。これは、AI がプラットフォーム固有のポリシーに従ってオンライン トラフィックを規制し、多数の人間による規制者の身体的および精神的負担を軽減できるという、デジタル プラットフォームの将来に対してより前向きなビジョンを提供します。利用可能なユーザーの種類: OpenAI API にアクセスできるユーザーは誰でも、このアプローチを実装して独自の AI 支援モデレーション システムを作成できます。## コンテンツモデレーションの課題コンテンツのモデレーションには細心の注意を払い、細心の注意を払い、コンテキストを深く理解し、新しいユースケースに迅速に適応する必要があるため、プロセスは時間がかかり、困難なものとなります。従来、このタスクの負担は人間のキュレーターにかかっており、キュレーターは、より小規模な業界固有の機械学習モデルのサポートを受けて、大量のコンテンツをふるいにかけ、有毒で有害な素材を除去していました。このプロセスは本質的にゆっくりとしたものであり、人間にとって精神的なストレスとなる可能性があります。## 大規模言語モデル (LLM) を使用して解決OpenAI 研究チームは、これらの課題に対処するために LLM の使用を検討しています。彼らは、GPT-4 などの大規模な言語モデルは自然言語を理解して生成できるため、コンテンツのモデレーションに適していると主張しています。これらのモデルは、提供されるポリシー ガイダンスに基づいて適度な判断を下すことができます。このシステムにより、コンテンツ モデレーション ポリシーの開発とカスタマイズのプロセスが数か月から数時間に短縮されました。1. レビュー用の政策ガイドラインが作成されると、政策専門家は少数の例を特定し、政策に従ってラベルを割り当てることでゴールデン データ セットを作成できます。2. GPT-4 はポリシーを読み取り、同じデータセットにラベルを割り当てますが、答えは表示されません。3. GPT-4 の判断と人間の判断との矛盾を調べることで、政策専門家は GPT-4 にそのラベルの背後にある理由を考え出し、政策定義のあいまいさを分析し、混乱を解決し、それに応じて政策についてのさらなる洞察を提供して明確にするよう依頼できます。ポリシーの品質に満足するまで、ステップ 2 と 3 を繰り返します。この反復プロセスにより、分類子に変換される洗練されたコンテンツ ポリシーが生成され、ポリシーとコンテンツのモデレーションを大規模に展開できるようになります。あるいは、大量のデータを大規模に処理するために、GPT-4 の予測を使用して小規模なモデルを微調整することもできます。このシンプルかつ強力なアイデアは、コンテンツ モデレーションの従来の方法にいくつかの改善をもたらします。ラベルの一貫性が向上しました。コンテンツ ポリシーは常に進化しており、多くの場合非常に詳細です。人によってポリシーの解釈が異なる場合があり、モデレータによっては新しいポリシーの変更を理解するのに時間がかかる場合があり、その結果、ラベル付けが不一致になる場合があります。対照的に、LL.M. は言葉遣いのニュアンスに敏感で、ポリシーの更新にすぐに適応して、一貫したコンテンツ エクスペリエンスをユーザーに提供します。より高速なフィードバック ループ。新しいポリシーを作成し、それらにラベルを付け、人間からのフィードバックを収集するというポリシー更新のサイクルは、多くの場合、長く続くプロセスです。 GPT-4 を使用すると、このプロセスを数時間に短縮でき、新たな危険に対してより迅速に対応できるようになります。精神的な負担を軽減します。有害なコンテンツや不快なコンテンツに常にさらされると、モデレータは精神的な疲労や心理的ストレスにつながる可能性があります。このようなタスクを自動化することは、関係者の幸福に役立ちます。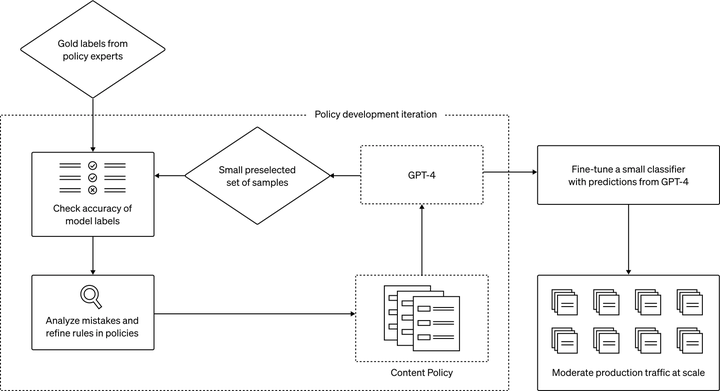 上の図は、GPT-4 がコンテンツ モデレーションにどのように使用されるか (ポリシーの開発から大規模なモデレーションまで) のプロセスを説明しています。何が安全で何が安全でないかに関するモデル自身の内部判断に主に依存する憲法 AI とは異なり、OpenAI のアプローチにより、プラットフォーム固有のコンテンツ ポリシーをより迅速に、より少ない労力で繰り返すことができます。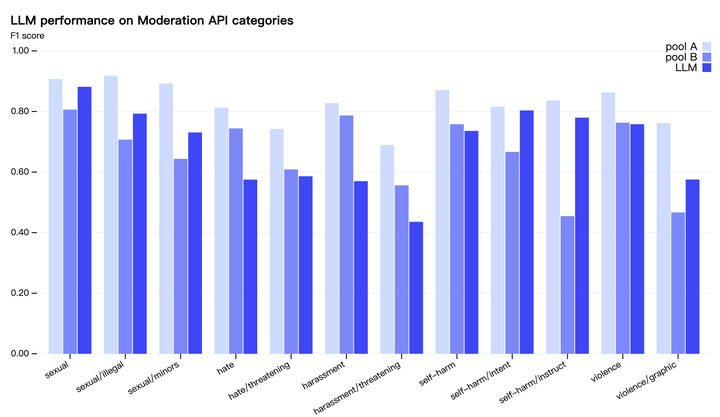 (上) GPT-4 のラベル品質は、軽い訓練を受けた人間のレビュー担当者 (プール B) と同様です。ただし、経験豊富で十分な訓練を受けた人間のモデレーター (プール A) は依然として両方を上回ります。OpenAI 研究チームは、連鎖推論や自己批判などを組み込むなど、GPT-4 の予測品質のさらなる向上を積極的に模索しています。同時に、未知のリスク手法の検出にも努めており、Constitutional AI からインスピレーションを得て、モデルを使用して潜在的に有害なコンテンツを特定し、有害なコンテンツの概要を説明することを目指しています。これらの調査結果は、既存のコンテンツ ポリシーの更新や、まったく新しいリスク領域を対象としたポリシーの開発に役立ちます。*注:Constitutional AI は、OpenAI の元メンバーによって設立された競合企業 Anthropic が、その大規模モデル製品 Claude 用に開発したメカニズムです。このメカニズムは、AI システムを人間の意図に合わせて調整する「原則ベースの」アプローチを提供することを目的としており、ChatGPT を可能にします。のようなモデルは、質問に答えるためのガイドとして単純な原則セットを使用します。 *


OpenAI チームは、コンテンツ レビュー システムを作成し、手動による参加を減らすための GPT-4 の最新の使用法をリリースしました。
8 月 16 日、OpenAI チームは AI の新たな利用法、つまりコンテンツ ポリシーの開発とコンテンツ モデレーションの決定に GPT-4 を使用することを発表しました。これにより、より一貫性のあるラベル付け、ポリシー改良のためのより迅速なフィードバック ループが可能になり、手動レビュー参加者の参加が減少します。
コンテンツのモデレーションは、デジタル プラットフォームの健全性を維持する上で重要な役割を果たします。 OpenAI の研究者は、GPT-4 を使用したコンテンツ モデレーション システムにより、ポリシーの変更をはるかに高速に繰り返すことができ、サイクル タイムが数か月から数時間に短縮されることを発見しました。
同時に、GPT-4 は、長いコンテンツ ポリシー文書のルールとニュアンスを解釈し、ポリシーの更新に即座に適応することもできるため、より一貫性のあるラベルが得られます。これは、AI がプラットフォーム固有のポリシーに従ってオンライン トラフィックを規制し、多数の人間による規制者の身体的および精神的負担を軽減できるという、デジタル プラットフォームの将来に対してより前向きなビジョンを提供します。
利用可能なユーザーの種類: OpenAI API にアクセスできるユーザーは誰でも、このアプローチを実装して独自の AI 支援モデレーション システムを作成できます。
コンテンツモデレーションの課題
コンテンツのモデレーションには細心の注意を払い、細心の注意を払い、コンテキストを深く理解し、新しいユースケースに迅速に適応する必要があるため、プロセスは時間がかかり、困難なものとなります。従来、このタスクの負担は人間のキュレーターにかかっており、キュレーターは、より小規模な業界固有の機械学習モデルのサポートを受けて、大量のコンテンツをふるいにかけ、有毒で有害な素材を除去していました。このプロセスは本質的にゆっくりとしたものであり、人間にとって精神的なストレスとなる可能性があります。
大規模言語モデル (LLM) を使用して解決
OpenAI 研究チームは、これらの課題に対処するために LLM の使用を検討しています。彼らは、GPT-4 などの大規模な言語モデルは自然言語を理解して生成できるため、コンテンツのモデレーションに適していると主張しています。これらのモデルは、提供されるポリシー ガイダンスに基づいて適度な判断を下すことができます。
このシステムにより、コンテンツ モデレーション ポリシーの開発とカスタマイズのプロセスが数か月から数時間に短縮されました。
この反復プロセスにより、分類子に変換される洗練されたコンテンツ ポリシーが生成され、ポリシーとコンテンツのモデレーションを大規模に展開できるようになります。
あるいは、大量のデータを大規模に処理するために、GPT-4 の予測を使用して小規模なモデルを微調整することもできます。
このシンプルかつ強力なアイデアは、コンテンツ モデレーションの従来の方法にいくつかの改善をもたらします。
ラベルの一貫性が向上しました。コンテンツ ポリシーは常に進化しており、多くの場合非常に詳細です。人によってポリシーの解釈が異なる場合があり、モデレータによっては新しいポリシーの変更を理解するのに時間がかかる場合があり、その結果、ラベル付けが不一致になる場合があります。対照的に、LL.M. は言葉遣いのニュアンスに敏感で、ポリシーの更新にすぐに適応して、一貫したコンテンツ エクスペリエンスをユーザーに提供します。
より高速なフィードバック ループ。新しいポリシーを作成し、それらにラベルを付け、人間からのフィードバックを収集するというポリシー更新のサイクルは、多くの場合、長く続くプロセスです。 GPT-4 を使用すると、このプロセスを数時間に短縮でき、新たな危険に対してより迅速に対応できるようになります。
精神的な負担を軽減します。有害なコンテンツや不快なコンテンツに常にさらされると、モデレータは精神的な疲労や心理的ストレスにつながる可能性があります。このようなタスクを自動化することは、関係者の幸福に役立ちます。
何が安全で何が安全でないかに関するモデル自身の内部判断に主に依存する憲法 AI とは異なり、OpenAI のアプローチにより、プラットフォーム固有のコンテンツ ポリシーをより迅速に、より少ない労力で繰り返すことができます。
OpenAI 研究チームは、連鎖推論や自己批判などを組み込むなど、GPT-4 の予測品質のさらなる向上を積極的に模索しています。同時に、未知のリスク手法の検出にも努めており、Constitutional AI からインスピレーションを得て、モデルを使用して潜在的に有害なコンテンツを特定し、有害なコンテンツの概要を説明することを目指しています。これらの調査結果は、既存のコンテンツ ポリシーの更新や、まったく新しいリスク領域を対象としたポリシーの開発に役立ちます。
*注:Constitutional AI は、OpenAI の元メンバーによって設立された競合企業 Anthropic が、その大規模モデル製品 Claude 用に開発したメカニズムです。このメカニズムは、AI システムを人間の意図に合わせて調整する「原則ベースの」アプローチを提供することを目的としており、ChatGPT を可能にします。のようなモデルは、質問に答えるためのガイドとして単純な原則セットを使用します。 *